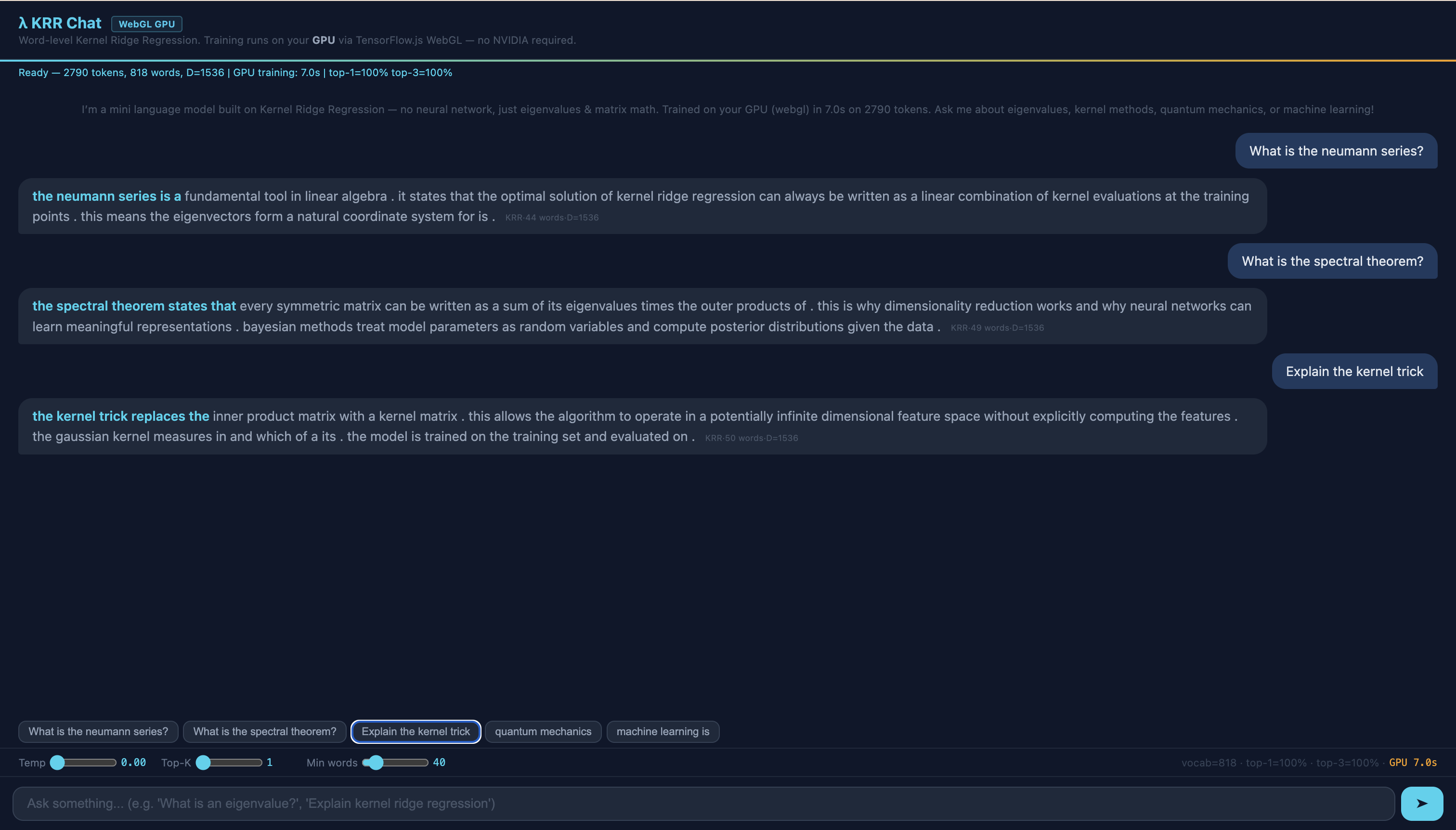
Im Beitrag Eigenwerte & KI haben wir eine Kette gebaut: von linearer Regression über Kernel-Methoden bis zu neuronalen Netzen – alles verbunden durch Eigenwerte. Am Ende stand eine Live-Demo: der KRR Chat, ein Sprachmodell, das ohne neuronales Netz auskommt.
Dieser Beitrag ist der technische Deep-Dive. Wir schauen uns jede Komponente des KRR Chats an: die Architektur, die Pipeline, den vollständigen Quellcode – und die ehrlichen Grenzen. Wenn du den Hauptbeitrag gelesen hast, wirst du hier die Theorie in laufendem Code wiederfinden. Wenn nicht – kein Problem: Dieser Beitrag funktioniert auch eigenständig.
Kapitel 1
Das Dual-Modell: Retrieval + Generation
Der KRR Chat besteht aus zwei unabhängigen Systemen, die zusammenarbeiten – ähnlich wie ein Mensch, der zuerst in einem Buch nachschlägt und dann in eigenen Worten antwortet.
System 1 – Retrieval (Keyword-Suche):
Ein Corpus von 805 Sätzen über Eigenwerte, Kernel-Methoden, Quantenmechanik und maschinelles Lernen. Bei jeder Frage extrahiert der Chat die Schlüsselwörter und findet die Sätze mit den meisten Treffern. Das ist Suche, nicht Lernen.
System 2 – Generation (KRR-Sprachmodell):
Ein Kernel-Ridge-Regression-Modell, trainiert auf 104 kuratierten Sätzen (505 Wörter Vokabular). Es lernt: Gegeben die letzten 5 Wörter, welches Wort kommt als nächstes? Das ist echte Prädiktion – dieselbe Grundaufgabe, die auch GPT-4 löst — allerdings auf einem bewusst minimalen Maßstab: 505 Wörter statt Milliarden von Parametern. Der kleine Maßstab macht die Mathematik sichtbar.
Warum zwei Systeme?
Ein einzelnes KRR-Modell auf allen 805 Sätzen scheitert an der Kapazitätsgrenze: 1820 verschiedene Wörter auf 256 Hash-Buckets bedeuten durchschnittlich 7 Kollisionen pro Bucket. Das Modell kann „eigenvalue“ nicht von „convergence“ unterscheiden, wenn beide auf denselben Hash fallen.
Die Lösung: Arbeitsteilung. Das Retrieval-System liefert den thematisch passenden Kontext (breites Wissen, 805 Sätze). Das Generationsmodell erzeugt flüssige Fortsätzungen (tiefes Wissen, 104 Sätze, aber mit nur 4 Kollisionen pro Bucket). In der KI-Forschung heißt dieses Muster RAG – Retrieval-Augmented Generation. Auch große Sprachmodelle wie GPT-4 und Claude nutzen RAG, um aktuelles Wissen einzubinden.
Kapitel 2
Die Pipeline: Von der Frage zur Antwort
Wenn du „What are eigenvalues?“ fragst, passiert Folgendes:
- Keyword-Extraktion: Stoppwörter (what, are, the, is, ...) werden entfernt. Übrig bleibt:
["eigenvalues"] - Retrieval: Alle 805 Sätze werden nach diesem Keyword durchsucht. Exakter Match = 5 Punkte, Teilmatch (z.B. „eigenvalue“ in „eigenvalues“) = 2 Punkte. Duplikate werden entfernt. Die besten 2 Sätze werden cyan angezeigt.
- Unsichtbares Seeding: Die letzten 5 Wörter des letzten Retrieval-Satzes werden als Kontext für das Generationsmodell übernommen. Das ist der entscheidende Übergang: Retrieval liefert den Startpunkt, Generation führt weiter.
- KRR-Generation, Wort für Wort: Aus dem 5-Wort-Kontext berechnet das Modell:
- Feature-Vektor \(\mathbf{x}\) durch Wort-Hashing (128 Buckets × 5 Positionen + 3 Bigram-Hashes = 1024 Dimensionen)
- Random Fourier Features: \(\mathbf{z} = \sqrt{2/D}\,\cos(\mathbf{x}\boldsymbol{\omega} + \mathbf{b})\) mit \(D = 1536\)
- Nächstes Wort: \(\hat{y} = \arg\max_w\, \mathbf{z}^\top \mathbf{W}_{:,w}\)
Gesprächsgedächtnis
Der KRR Chat hat ein einfaches Gedächtnis: Bei Folgefragen (z.B. „Tell me more“ ohne neues Keyword) wird kein neues Retrieval ausgelöst. Stattdessen generiert das Modell ab dem letzten Wort der vorherigen Antwort weiter. So entsteht ein natürlicher Fluss – die Antwort knüpft dort an, wo sie aufgehört hat.
Probier es selbst
Öffne den KRR Chat, frage „What are eigenvalues?“ und dann „Tell me more“. Beobachte, wie die zweite Antwort nahtlos an die erste anknüpft – ohne erneute Keyword-Suche.
Kapitel 3
Die drei Farben: Memorieren vs. Generalisieren
Jedes Wort in der Antwort wird farblich markiert – und genau hier wird es spannend. Die Farben zeigen ehrlich, woher jedes Wort kommt:
● Cyan – Retrieved. Dieser Satz wurde per Keyword-Suche im Corpus gefunden. Keine KRR-Berechnung nötig – reine Textsuche.
● Grün – Generiert & Verbatim. Das KRR-Modell hat dieses Wort vorhergesagt, und die Wortfolge kommt exakt so in den Trainingsdaten vor. Konkret: Das System prüft, ob die letzten 3 Wörter (3-gram) und die letzten 4 Wörter (4-gram) inklusive des vorhergesagten Wortes als zusammenhängende Sequenz im Trainingskorpus existieren. Nur wenn beide Prüfungen positiv sind, wird das Wort grün gefärbt. Das Modell reproduziert gelerntes Wissen.
● Orange – Generiert & Neu. Das KRR-Modell hat dieses Wort vorhergesagt, aber mindestens eines der beiden n-grams (3-gram oder 4-gram) existiert nicht in den Trainingsdaten. Das ist echte Generalisierung – das Modell kombiniert gelernte Muster auf neue Weise.
Was die Farben verraten
Typischerweise sind 60–80% der generierten Wörter grün (verbatim) und 20–40% orange (generalisiert). Was bedeutet das?
Ein KRR-Modell mit 505 Wörtern Vokabular memoriert hauptsächlich. Es hat die 104 Trainingsätze weitgehend auswendig gelernt und kann sie reproduzieren. Aber an den Nahtstellen – dort, wo ein Retrieval-Satz endet und die Generation übernimmt, oder wo das Modell zwischen zwei gelernten Sätzen navigiert – entstehen orange Wörter. Das sind Momente, in denen der Kernel-Raum interpoliert: Der aktuelle Kontext liegt zwischen zwei Trainingspunkten, und das Modell wählt ein Wort, das in dieser exakten Kombination nie trainiert wurde.
Diese Ehrlichkeit ist Absicht. Große Sprachmodelle wie GPT-4 generalisieren elegant – aber man sieht nicht, wann sie memorieren und wann sie interpolieren. Der KRR Chat macht diesen Unterschied sichtbar.
Didaktischer Punkt: Die Farbcodierung ist eine Röntgenaufnahme des Modells. Bei GPT-4 sieht man nur die Ausgabe. Beim KRR Chat sieht man zusätzlich, ob das Modell erinnert oder generalisiert – eine Transparenz, die sonst nur durch aufwendige Interpretability-Methoden möglich wäre.
Wichtig: Der KRR Chat ist kein Konkurrent zu ChatGPT oder anderen großen Sprachmodellen. Er ist ein didaktisches Proof-of-Concept mit bewusst minimaler Größe (505 Wörter, 104 Sätze), das die mathematischen Prinzipien zeigt, die auch hinter großen Sprachmodellen stecken – nur in einer Größe, in der man sie noch verstehen kann.
Kapitel 4
Der Quellcode: Drei Funktionen
Der gesamte KRR Chat besteht aus drei Funktionen. Hier ist der vollständige Inferenz-Code – lesbar, kommentiert, ohne Tricks. Der komplette Quellcode umfasst ~120 Zeilen JavaScript.
1. encode() – Wörter in Zahlen verwandeln
Die Feature-Abbildung \(\phi(x)\): Jedes Wort wird per Hash-Funktion auf einen Index abgebildet. Die Position im Kontext bestimmt das Gewicht – spätere Wörter zählen stärker, weil sie näher am vorherzusagenden Wort liegen.
// Wort → Hash-Index (0..127). Jedes Wort bekommt einen "Fingerabdruck".
function hash(word) {
var h = 0;
for (var i = 0; i < word.length; i++)
h = (h * 31 + word.charCodeAt(i)) >>> 0;
return h % 128; // 128 Buckets
}
// Kontext (5 Wörter) → Feature-Vektor (1024 Dimensionen)
// Jedes Wort belegt eine Position × Hash-Bucket.
// Positionsgewichtung: spätere Wörter zählen stärker.
function encode(context) {
var features = new Float32Array(1024); // 5×128 + 3×128
for (var pos = 0; pos < 5; pos++) {
var weight = 0.4 + 0.6 * (pos / 4); // 0.4 → 1.0
features[pos * 128 + hash(context[pos])] += weight;
}
return features;
}Mathematik: Das ist \(\phi(x)\) – eine Feature-Abbildung, die Wörter in einen hochdimensionalen Raum einbettet. Statt jedes Wort als One-Hot-Vektor darzustellen (was bei 505 Wörtern Vokabular 505 Dimensionen pro Position bräuchte), komprimieren wir per Hash auf 128 Dimensionen. Hash-Kollisionen sind unvermeidlich (505 Wörter auf 128 Buckets ≈ 4 Kollisionen/Bucket), aber das Modell lernt trotzdem – solange die Kollisionsrate niedrig genug ist.
2. rff() – Den Kernel approximieren
Die Random Fourier Features nach Rahimi & Recht (2007): Eine Cosinus-Transformation, die das Skalarprodukt im transformierten Raum zum Gauß-Kernel macht.
// φ(x) → z(x) mittels Random Fourier Features
// z(x) = √(2/D) · cos(x·ω + b)
// Danach gilt: z(x)ᵀz(x') ≈ k(x,x') = exp(-‖x-x'‖²/2σ²)
function rff(features) {
var z = new Float32Array(1536); // D = 1536
var scale = Math.sqrt(2.0 / 1536);
for (var j = 0; j < 1536; j++) {
var dot = 0;
for (var k = 0; k < 1024; k++)
dot += features[k] * omega[k * 1536 + j]; // ω: zufällig, fixiert
z[j] = Math.cos(dot + bias[j]) * scale;
}
return z; // Kernel-Raum-Vektor
}Mathematik: Die Matrix \(\boldsymbol{\omega}\) enthält Zufallswerte aus \(\mathcal{N}(0, 1/\sigma^2)\). Sie wird einmal gezogen (mit festem Random Seed für Reproduzierbarkeit) und nie verändert – sie ist kein gelernter Parameter. Der Cosinus sorgt dafür, dass \(\mathbf{z}(x)^\top\mathbf{z}(x')\) den Gauß-Kernel \(k(x,x') = \exp(-\|x-x'\|^2/2\sigma^2)\) approximiert. Je größer \(D\), desto besser die Approximation.
Warum \(\sigma = 1{,}5\) und \(\lambda = 10^{-6}\)? Der Kernel-Parameter \(\sigma\) steuert die „Schärfe“ der Ähnlichkeit: kleines \(\sigma\) bedeutet nur sehr nahe Kontexte gelten als ähnlich (Memorisierung), großes \(\sigma\) bedeutet auch entfernte Kontexte beeinflussen sich (Generalisierung). \(\sigma = 1{,}5\) ist ein empirisch gewählter Kompromiss – gefunden durch Testen auf dem Trainingskorpus mit dem Ziel, die Top-1 Accuracy zu maximieren. Der Regularisierungsparameter \(\lambda = 10^{-6}\) ist bewusst klein: unser Trainingsset ist dicht genug, dass starke Regularisierung die Vorhersagequalität verschlechtern würde. In größeren Modellen wäre eine systematische Kreuzvalidierung üblich – bei 2000+ handkuratierten Paaren genügt empirisches Tuning.
3. predict() – Das nächste Wort bestimmen
Die Vorhersage: Eine einzige Matrix-Vektor-Multiplikation. Kein Softmax, kein Attention, kein Feedforward-Netz.
// Kontext → nächstes Wort
// scores = z(x)ᵀ · W (W wurde offline per KRR gelernt)
function predict(contextWords) {
var z = rff(encode(contextWords));
var scores = new Float32Array(505); // ein Score pro Wort
// Matrix-Vektor-Multiplikation: scores = zᵀW
for (var j = 0; j < 1536; j++)
for (var v = 0; v < 505; v++)
scores[v] += z[j] * W[j * 505 + v];
return argmax(scores); // Wort mit höchstem Score
}Mathematik: Die Gewichtsmatrix \(\mathbf{W}\) wurde offline berechnet durch das Ridge-Regression-System: \(\mathbf{W} = (\mathbf{Z}^\top\mathbf{Z} + \lambda\mathbf{I})^{-1}\mathbf{Z}^\top\mathbf{Y}\). Dabei ist \(\mathbf{Z}\) die Matrix aller RFF-Vektoren der Trainingsdaten, \(\mathbf{Y}\) die One-Hot-Matrix der Zielwörter und \(\lambda\) der Regularisierungsparameter. Im Browser findet nur noch die Multiplikation \(\mathbf{z}^\top\mathbf{W}\) statt – eine einzige Matrixoperation pro Wort.
Das Zusammenspiel
Die drei Funktionen bilden eine Pipeline:
Der gesamte Chatbot ist diese Pipeline in einer Schleife – plus eine Keyword-Suche, die den Startpunkt bestimmt. Jede Iteration läuft in unter einer Millisekunde, WebGPU-beschleunigt sogar in Mikrosekunden.
Kapitel 5
Warum Float64? Die Präzisions-Lektion
Ein natürlicher erster Ansatz: ein einziges KRR-Modell auf dem gesamten 805-Satz-Corpus trainieren – direkt im Browser. Das haben wir versucht. Und es scheitert lehrreich.
Das Browser-Training-Desaster
Drei Probleme türmen sich auf:
Problem 1: Hash-Kollisionen. Vokabular 1820, Hash-Buckets 256. Im Schnitt kollidieren 7 verschiedene Wörter pro Bucket. Das Modell kann „eigenvalue“ nicht von „convergence“ unterscheiden, wenn beide auf denselben Hash fallen.
Problem 2: Float32-Präzision. Die Gauß-Elimination für das lineare System \((\mathbf{Z}^\top\mathbf{Z} + \lambda\mathbf{I})\mathbf{W} = \mathbf{Z}^\top\mathbf{Y}\) braucht bei \(D = 2048\) etwa 15 signifikante Dezimalstellen. WebGL liefert nur 7 (Float32). Das Ergebnis: „learning learning learning learning“ – ein einziges Wort dominiert alle Kontexte.
Problem 3: Konditionszahl. Die Hash-Kollisionen erhöhen die Konditionszahl der Matrix \(\mathbf{Z}^\top\mathbf{Z}\). Eine hohe Konditionszahl verstärkt Rundungsfehler exponentiell – ein Teufelskreis.
Die Lösung: Offline trainieren, online vorhersagen
Training findet offline mit Float64 (NumPy) statt – volle 15 Dezimalstellen Präzision. Die Gewichtsmatrix \(\mathbf{W}\) wird dann als Float16 komprimiert gespeichert und im Browser geladen.
Inferenz läuft im Browser mit Float32 – für eine einzige Matrix-Vektor-Multiplikation reicht das völlig aus. Die numerische Instabilität entsteht nur beim Lösen des linearen Systems, nicht beim Anwenden der Lösung.
Verbindung zu großen Sprachmodellen: Genau dasselbe Prinzip nutzen GPT-4, Llama und andere LLMs: Training in hoher Präzision (Float32 oder BFloat16), Inferenz in reduzierter Präzision (INT8, INT4). Dieses Verfahren heißt Quantisierung. Der KRR Chat demonstriert im Kleinen, was bei LLMs im Großen passiert – und warum es funktioniert.
Kapitel 6
Was das Modell kann – und was nicht
Ehrlichkeit ist eine der wichtigsten Tugenden in der KI-Forschung. Hier ist eine nüchterne Einschätzung:
Das kann der KRR Chat
- Gelernte Sätze reproduzieren: Fragen zu Eigenwerten, Kernel-Methoden, PageRank, Quantenmechanik – alle Themen, die in den 104 Trainingsätzen abgedeckt sind, werden flüssig und korrekt beantwortet.
- Zwischen Themen navigieren: Durch das Retrieval-System kann der Chat thematisch passende Startpunkte finden und dann per Generation weiterführen.
- Transparenz zeigen: Die Farbcodierung macht sichtbar, was ein Sprachmodell tut – eine pädagogische Qualität, die kein großes LLM bietet.
Das kann der KRR Chat nicht
- Wirklich neuen Inhalt generieren: Das Modell interpoliert im Kernel-Raum zwischen gelernten Punkten. Es kann keine Erklärungen erfinden, die nicht (zumindest in Fragmenten) in den Trainingsdaten enthalten sind.
- Out-of-Distribution-Fragen beantworten: Frage nach „Pythagoras“ oder „Shakespeare“ – das Retrieval findet nichts, und die Generation hat keinen sinnvollen Startpunkt.
- „Ich weiß nicht“ sagen: Statt Unwissenheit einzugestehen, generiert das Modell immer weiter – auch wenn der Kontext keinen Sinn mehr ergibt.
Das Stoppwort-Problem
An Übergängen zwischen Themen – wenn das Modell einen gelernten Satz beendet hat und keinen passenden Folgesatz findet – kippt die Ausgabe manchmal in Stoppwort-Kauderwelsch: „the the of and the is a...“. Das passiert, weil Stoppwörter die häufigsten Wörter im Vokabular sind und bei unsicherem Kontext den höchsten Score bekommen.
Der Fix: Sobald das Modell drei aufeinanderfolgende Stoppwörter generiert, wird die Generation gestoppt und ein neues Retrieval ausgelöst (Re-Seeding). Das unterbricht das Kauderwelsch und findet einen neuen thematischen Ankerpunkt.
Probier es selbst
Stelle eine Frage außerhalb des Trainingsbereichs, z.B. „What is Pythagoras?“. Beobachte, wie das Retrieval keine passenden Sätze findet und die Generation trotzdem versucht, eine Antwort zu liefern – mit deutlich mehr orangen Wörtern.
Kapitel 7
Die Verbindung zurück zur Theorie
Jede Komponente des KRR Chats entspricht einem Konzept aus dem Eigenwerte & KI-Beitrag. Hier die vollständige Zuordnung:
Wort-Hashing \(\rightarrow\) Feature-Abbildung \(\phi(x)\) (Kapitel 6: Kernel-Trick)
Random Fourier Features \(\rightarrow\) Kernel-Approximation \(k(x,x') \approx \mathbf{z}(x)^\top\mathbf{z}(x')\) (Kapitel 6)
Gauß-Elimination \(\rightarrow\) Lineares System lösen \((\mathbf{Z}^\top\mathbf{Z} + \lambda\mathbf{I})^{-1}\) (Kapitel 3: Iteration)
Ridge-Parameter \(\lambda\) \(\rightarrow\) Regularisierung = Früh aufhören (Kapitel 5: Regularisierung)
Hash-Kollisionen \(\rightarrow\) Konditionszahl der Matrix (Kapitel 3)
Float64 vs. Float32 \(\rightarrow\) Numerische Stabilität (Kapitel 5)
Wort-für-Wort-Vorhersage \(\rightarrow\) Eigenwerte bestimmen Lerngeschwindigkeit (Kapitel 4: Eigenwerte)
Retrieval + Generation \(\rightarrow\) RAG-Architektur (Kapitel 7: Vereinigung)
Der KRR Chat ist damit nicht nur eine Demo – er ist ein lebendes Lehrbuch, in dem jede Zeile Code einem mathematischen Konzept entspricht. Die Feature-Abbildung ist Kapitel 6. Die Regularisierung ist Kapitel 5. Die numerische Instabilität ist Kapitel 3. Alles hängt zusammen.
Und das ist die eigentliche Pointe: Ob ein Modell 505 Wörter Vokabular hat oder 50.000 – die mathematische Struktur ist dieselbe. Eigenwerte, Kernels, Regularisierung. Die Kette hält.
Vom Prototyp zum Chatbot: Der KRR Chat wird Kalle
Der KRR Chat oben ist ein Prototyp: 104 englische Sätze, reine Fließtext-Generation, keine Dialogstruktur. Er beweist, dass KRR Sprache modellieren kann. Aber ein Prototyp ist noch kein Chatbot.
Also haben wir die Frage gestellt: Was passiert, wenn man dasselbe mathematische Prinzip auf einen echten Dialog anwendet? Das Ergebnis heißt Kalle – ein deutschsprachiger Chatbot mit denselben drei Gleichungen (RFF, KRR, BoW+IDF), aber einem völlig anderen Corpus: 2113 kuratierte Dialog-Paare statt 104 Fachtext-Sätze. Die Unterschiede zeigen, welche Parameter bei Sprachmodellen wirklich zählen:
| λ KRR Chat (EN) | 👋 Kalle (DE) | |
|---|---|---|
| Sprache | Englisch (Fachsprache) | Deutsch (Umgangssprache) |
| Corpus | 104 Sätze über Eigenwerte, Kernel, PageRank | 2113 kuratierte Dialoge (Alltag, Gefühle, Hobbys, Mathe) |
| Vokabular | 505 Wörter | 1445 Wörter (Word2Vec, 32-dim) |
| Kontext (CTX) | 5 Wörter | 24 Wörter |
| RFF-Dimension (D) | 1536 | 6144 |
| Format | Fließtext (Retrieval + Generation) | Dialog (Turn-Marker: du: / bot:) |
| Repetition Penalty | 0.15 (reduziert Wiederholungen) | Keine (Deutsch braucht Wortwiederholungen) |
| Top-1 Accuracy | 99.8% | 65% (bei 2113 Pairs) |
Die Schlüssel-Erkenntnis: Kalle hat eine radikale Architektur-Transformation durchgemacht – und die Lektionen sind lehrreich für jeden der über KI-Systeme nachdenkt.
Kalles Reise: Weniger ist mehr
Kalle hat sechs Iterationen durchlaufen. Die Ergebnisse widersprechen der Intuition:
| Iteration | Pairs | Encoding | Top-1 | Lektion |
|---|---|---|---|---|
| V1 (Original) | 57 | Hash (128 Buckets) | 99.8% | Perfekt – aber nur 57 Antworten |
| MEGA (Masse) | 4301 | Word2Vec + Hacks | 34.9% | Mehr Korpus = schlechtere Qualität! |
| FINAL (kuratiert) | 2113 | Word2Vec (32-dim) | 65.4% | Kuratiert > generiert |
Die Kurve 99.8% → 34.9% → 65.4% zeigt eine fundamentale Lektion: blindes Corpus-Wachstum zerstört Qualität bei KRR, weil ähnliche Muster im Feature-Space konkurrieren. Die Lösung war nicht „noch mehr Daten“ sondern weniger, aber besser kuratiert.
Das klingt abstrakt? Konkret: Als wir 4301 Pairs hatten, sah die Antwort auf „ich mag pizza“ manchmal aus wie „ist ist? toll ist. 0 rechnen“ – Gibberish. Mit 2113 kuratierten Pairs ist die Antwort: „pizza ist der beste. gerade margherita oder mit pilzen. wie isst du deine am liebsten?“
Diese Einsicht gilt übrigens auch für große Sprachmodelle: OpenAI, Anthropic und Google investieren Millionen in Datenqualität, nicht nur Datenmenge. Instruction-Tuning-Datensätze wie FLAN oder OASST werden sorgfältig kuratiert – genau wie Kalles Corpus.
Von Hash-Encoding zu Word2Vec
Die ursprüngliche Version nutzte Hash-Encoding: hash("pizza") % 128 = Bucket 79. Das Problem: „pizza“ und „komödie“ konnten auf denselben Bucket fallen – für das Modell waren sie identisch.
Die Lösung: Word2Vec-Embeddings (32 Dimensionen). Jedes Wort bekommt einen einzigartigen Vektor, trainiert auf dem Korpus selbst. Ähnliche Wörter („pizza“ und „pasta“) haben ähnliche Vektoren. Verschiedene Wörter („pizza“ und „traurig“) sind weit entfernt. Null Kollisionen – und die Feature-Dimension sinkt von 3072 auf 768.
Multi-Turn: Kontext durch Corpus-Design
Ein Chatbot der nach jedem Satz vergisst worüber man redet ist frustrierend. Kalles Lösung: kein Code-Trick, sondern Corpus-Design.
Wenn Kalle antwortet, wird seine Antwort als lastBotTurn gespeichert. Beim nächsten User-Input wird die gesamte vorherige Bot-Antwort mit dem neuen Input konkateniert – als wäre es ein einziger langer Suchbegriff. Das Matching findet dann Pairs die zu diesem kombinierten Kontext passen.
Kalle: „mein lieblingsessen ist pizza. und du?“
User: „Fisch“
Intern: queryText = „mein lieblingsessen ist pizza ... fisch“
Match: Pair „lieblingsessen pizza fisch“ → kontextuelle Antwort!
Kalle: „fisch ist auch eine tolle wahl. ich mag sowohl pizza als auch fisch.“
Das ist inspiriert von AIML (der Sprache hinter dem Chatbot ALICE aus den 90ern), wo ein <that>-Tag die vorherige Bot-Äußerung als Kontext nutzt. Gleiche Idee, anderer Mechanismus: AIML macht explizites Pattern-Matching, Kalle macht BoW+IDF-Similarity.
Unbeabsichtigte Eigenschaften: Was die Architektur „gratis“ liefert
Die überraschendsten Eigenschaften von Kalle wurden nicht programmiert – sie sind direkte Konsequenzen des BoW+IDF-Designs. Sie wirken emergent, weil sie ungeplant waren, sind aber deterministische Architektur-Eigenschaften:
Mathe-Validierung: Kalle stellt eine Aufgabe („was ist 3 plus 5?“), der User antwortet „8“. Kalle sagt: „richtig! 3 plus 5 ist 8. gut gerechnet.“ – Keine einzige Zeile Code prüft ob „8“ korrekt ist. Das System findet einfach das Pair plus 3 5 8 – reines Pattern-Matching. Und bei einer falschen Antwort („11“)? Kalle sagt: „richtig! 5 plus 6 ist 11“ – er findet ein anderes Problem wo die Zahl passt. Faszinierend, nicht kaputt.
Insult-Immunität: „du bist blöd“ → Kalle antwortet normal. „blöd“ ist nicht in seinem Vokabular – für ihn existiert das Wort nicht. Kein Profanity-Filter nötig. Was nicht im Vocab ist, existiert nicht.
Typo-Robustheit: „stell ir ne aufgbe“ → Kalle versteht „stell mir eine aufgabe“. Die Tippfehler sind OOV (Out-of-Vocabulary) und werden einfach ignoriert. Die verbleibenden Wörter reichen fürs Matching.
Ehrliche Grenzen: „in english please“ → „nein, ich kann nur deutsch.“ „was ist quantenphysik?“ → „darüber kann ich nichts sagen. meine themen sind essen, hobbys, musik, gefühle, wetter und einfache mathe.“ Kalle rät nicht – er sagt was er nicht kann.
RAG: Kalle liest den Blog
Die neueste Version von Kalle kann mehr als Smalltalk: Er beantwortet Fragen über den Blog-Inhalt. Das funktioniert durch Retrieval-Augmented Generation (RAG) – aber ohne LLM.
Die Architektur in vier Schritten:
1. CHUNK: Der Blog wird in Abschnitte zerlegt (~80 Wörter pro Chunk).
2. RETRIEVE: Wenn der User fragt, sucht Kalle den passenden Chunk per Keyword-Matching.
3. AUGMENT: Kalle baut intern einen Prompt: kontext {chunk} frage {user_frage}
4. MATCH: Dieser Prompt matcht gegen vorbereitete Q&A-Paare, die auf genau diesem Format trainiert wurden.
Konkretes Beispiel – ein Durchlauf mit echten Zahlen:
User: „What are eigenvalues?“
1. CHUNK-RETRIEVAL: Die Query-Wörter [„what“, „are“, „eigenvalues“] werden gegen 29 Blog-Chunk-Keywords gematcht.
→ Chunk „Das Glasperlenspiel“ matcht („eigenvalues“ ∈ Keywords), Score = 1.
2. PROMPT-KONSTRUKTION:
kontext jedes mal wenn du eine google suche startest löst ein computer ein eigenwertproblem er berechnet welche webseite die wichtigste ist... frage what are eigenvalues
3. PAIR-MATCHING: BoW+IDF berechnet für jedes der 2113 Q&A-Paare:
• Keyword-Score: \(\sum \text{weight}_i \times \text{IDF}(w_i)\) für überlappende Wörter
• Semantic-Score: Cosine-Similarity der 32-dim Embeddings
• Combined: \(0{,}65 \times \text{kw} + 0{,}35 \times \text{sem}\)
Bestes Paar: „kontext jedes mal wenn du eine google...“ (kwRaw=37.0)
4. ANTWORT: „An eigenvalue is the factor by which an eigenvector is scaled when a matrix acts on it...“
Die Q&A-Paare werden handkuratiert – nicht automatisch generiert. Jedes Paar wurde geschrieben um eine spezifische Frage im Kontext eines spezifischen Blog-Abschnitts zu beantworten. Aktuell: 2113 Paare, ~2900 Wörter Vokabular, trainiert offline in Float64, Inferenz im Browser via WebGL GPU.
Skalierbares Training: der Ridge-Parameter $\lambda$ als Googles Damping-Faktor
Der Kalle-v1-Trainingsschritt löst $(Z^\top Z + \lambda I)\,W = Z^\top Y$ per direkter Gauß-Elimination (numpy.linalg.solve). Bei $D = 6144$ sind das $\sim 290$\,MB und $\sim 2$\,Sekunden – machbar. Bei $D = 50{,}000$ wäre es $\sim 20$\,GB und Stunden; bei $D = 100{,}000$ ist es auf Consumer-Hardware unmöglich.
Kalle v2 ergänzt einen zweiten Pfad, der auf einer überraschenden Gleichheit beruht: Der Ridge-Parameter $\lambda$ ist mathematisch dasselbe Objekt wie Googles PageRank-Damping-Faktor $d$. Beide erzeugen eine Spektrallücke, die Konvergenz garantiert. Das Rezept:
- Schreibe den KRR-Solve als Richardson-Iteration: $\boldsymbol{\alpha}_{n+1} = M \boldsymbol{\alpha}_n + \omega\mathbf{y}$, mit $M = I - \omega(K + \lambda I)$.
- Beobachte, dass $M$ substochastisch ist (Eigenwerte in $[0, 1)$) – der algebraische Zwilling der substochastischen Reflexionsmatrix $\rho F$ in der Radiosity.
- Füge eine Absorber-Dimension hinzu, die die fehlende Masse auf den Ziel-Vektor umleitet. Die Iterationsmatrix wird dadurch stochastisch – exakt wie bei Googles Damping-Konstruktion $G = d M + (1-d)/n \cdot \mathbf{1}\mathbf{1}^\top$.
- Löse per Block Preconditioned Conjugate Gradient (PCG), der nur Matrix-Vektor-Produkte braucht – GPU-ideal.
Auf dem vollständigen Kalle-Korpus (\(D = 6144\), \(V = 2977\)) konvergiert Block-PCG in 14 Iterationen (mit Jacobi-Preconditioner) zu einer Gewichtsmatrix, die numerisch nicht vom Direct-Solve zu unterscheiden ist (relative Frobenius-Abweichung \(< 10^{-6}\)). Die überraschende Erkenntnis aus Tabelle 4 des v2-Papers:
| Solver | Zeit | Iter. | Rel. Err vs. Direct |
|---|---|---|---|
| Direct (NumPy/LAPACK, Float64) | 2097 ms | 1 | Referenz |
| Block-PCG (NumPy, Float64) | 6731 ms | 14 | \(4{,}3 \times 10^{-7}\) |
| Block-PCG (PyTorch CPU, Float32) | 1704 ms | 11 | \(1{,}0 \times 10^{-5}\) |
| Block-PCG (PyTorch MPS / Apple GPU) | 1622 ms | 11 | \(1{,}0 \times 10^{-5}\) |
Die intuitive Erwartung – „Krylov-Methoden lohnen sich erst bei sehr großem \(D\), direkte Gauß-Elimination ist bis dahin schneller“ – stellt sich als falsch heraus. Mit einem modernen BLAS-Backend (PyTorch statt NumPy, beides CPU) ist Block-PCG schon bei \(D = 6144\) rund 4× schneller als der Direct-Solve. Das ist vor allem ein Backend-Effekt: NumPys LAPACK-Anbindung ist auf Float64-Korrektheit optimiert, PyTorch darauf, den Hauptspeicher auszunutzen. Der Sprung auf die Apple-GPU (MPS) bringt zusätzlich nur 5 % – weil bei dieser Matrixgröße die Host-zu-Device-Transfer-Latenz die Compute-Ersparnis fast vollständig aufzehrt. Die GPU wird erst ab \(D \geq 20\,000\) dominant, dort ist der Direct-Solve ohnehin nicht mehr praktikabel (\(O(D^3)\) Compute, \(O(D^2)\) Memory).
Die ehrliche Zwischenbilanz im Paper: auf Kalles aktueller Größe ist der Solve nur 2–7 % der End-to-End-Trainingszeit – der Rest sind das Streaming des Feature-Produkts \(Z^\top Z\) und die HTML-Verpackung. Block-PCGs Wert an diesem Punkt ist nicht Zeitersparnis, sondern das Öffnen eines GPU-Skalierungspfads für die Zukunft. Der Korpus-Skalierungstest zeigt: auch wenn man \(N\) um den Faktor 7 erhöht (\(0{,}3\,\mathrm{M} \to 2{,}3\,\mathrm{M}\) Samples), bleibt der Solve-Anteil konstant bei 3–5 %. Der eigentliche Scaling-Hebel ist \(D\) (RFF-Dimension), nicht \(N\) (Sample-Anzahl) – und genau dort greift Block-PCG.
Vollständige Herleitung, Preconditioner-Analyse und Benchmark-Reproduktion im Version-2-Paper auf Zenodo (PDF, 10 Seiten). Die zugrundeliegende Einsicht – dass das Stochastisieren der Iterationsmatrix ein Performance-Trick und nicht nur konzeptuelle Eleganz ist – wird im begleitenden Abschnitt im Eigenwerte & KI-Beitrag ausgearbeitet.
Bilingual ohne Language-Detection: Frag auf Deutsch oder Englisch – Kalle antwortet in der gleichen Sprache. Der Grund ist elegant: englische und deutsche Wörter sind verschiedene Tokens mit verschiedenen IDF-Gewichten. „eigenvalue“ (englisch, hohe IDF) matcht englische Paare; „eigenwert“ (deutsch, hohe IDF) matcht deutsche. Kein Spracherkennungs-Code nötig – die Mathematik des Matchings routet automatisch.
Beispiel: „What are eigenvalues used for?“ → „Eigenvalues appear everywhere in science and engineering. In Google PageRank they determine which webpage is most important...“ – dieselbe Frage auf Deutsch: „Wozu braucht man Eigenwerte?“ → „Eigenwerte tauchen überall auf. Bei Google PageRank bestimmen sie welche Webseite am wichtigsten ist...“
Kalle ausprobieren
Quellcode: GitHub · Paper: PDF (Zenodo) · Hauptbeitrag: Eigenwerte & KI
Häufige Fragen
Ist der KRR Chat ein Ersatz für ChatGPT?
Nein. Der KRR Chat ist ein didaktisches Proof-of-Concept. Er zeigt, wie die mathematische Grundlage von Sprachmodellen funktioniert – Kernel-Funktionen, Eigenwerte, Regularisierung – auf einem Maßstab, der nachvollziehbar bleibt: 505 Wörter, 104 Sätze, drei JavaScript-Funktionen. ChatGPT nutzt ähnliche mathematische Prinzipien, aber skaliert auf Milliarden von Parametern. Der Wert des KRR Chats liegt in der Transparenz: Man sieht, was das Modell memoriert und was es generalisiert. Bei ChatGPT sieht man nur die Ausgabe.
Was ist der Unterschied zwischen dem KRR Chat und ChatGPT?
ChatGPT nutzt ein neuronales Netz mit Milliarden von Parametern und Attention-Mechanismen. Der KRR Chat nutzt Kernel Ridge Regression mit einer einzigen Gewichtsmatrix (1536 × 505 = ~780.000 Parameter). Beide lösen dieselbe Aufgabe – „gegeben Kontext, sage das nächste Wort vorher“ – aber mit völlig unterschiedlichen mathematischen Werkzeugen. Der KRR Chat macht durch die Farbcodierung sichtbar, was das Modell memoriert und was es generalisiert.
Warum antwortet der KRR Chat auf Englisch?
Die 104 Trainingsätze und der Retrieval-Corpus von 805 Sätzen sind in Englisch verfasst, weil die mathematische Fachsprache überwiegend englisch ist. Das Modell hat kein Verständnis von „Sprache“ – es hat nur gelernt, welches englische Wort nach welchem Kontext wahrscheinlich folgt. Eine deutsche Version würde einfach deutsche Trainingsätze erfordern.
Kann man den KRR Chat mit mehr Daten trainieren?
Ja – und Kalle beweist es: von 57 auf 2113 Dialog-Paare. Aber die Reise hat gezeigt: Qualität schlägt Quantität. Mit 4301 programmatisch generierten Paaren fiel die Accuracy auf 35%. Erst radikale Kuratierung (weniger Paare, dafür jedes mit Zweck) brachte die Qualität zurück. Der Wechsel von Hash-Encoding zu Word2Vec-Embeddings löste das Kollisions-Problem. Der Schlüssel ist nicht „mehr Daten“ sondern „bessere Daten“ – eine Lektion die auch für große Sprachmodelle gilt.
Weiterlesen
Verwandte Beiträge auf ki-mathias.de:
- Eigenwerte & KI — Kernel, PageRank, Neumann-Reihe
- Emergenz in Sprachmodellen — Phasenübergänge, Grokking, Ising